
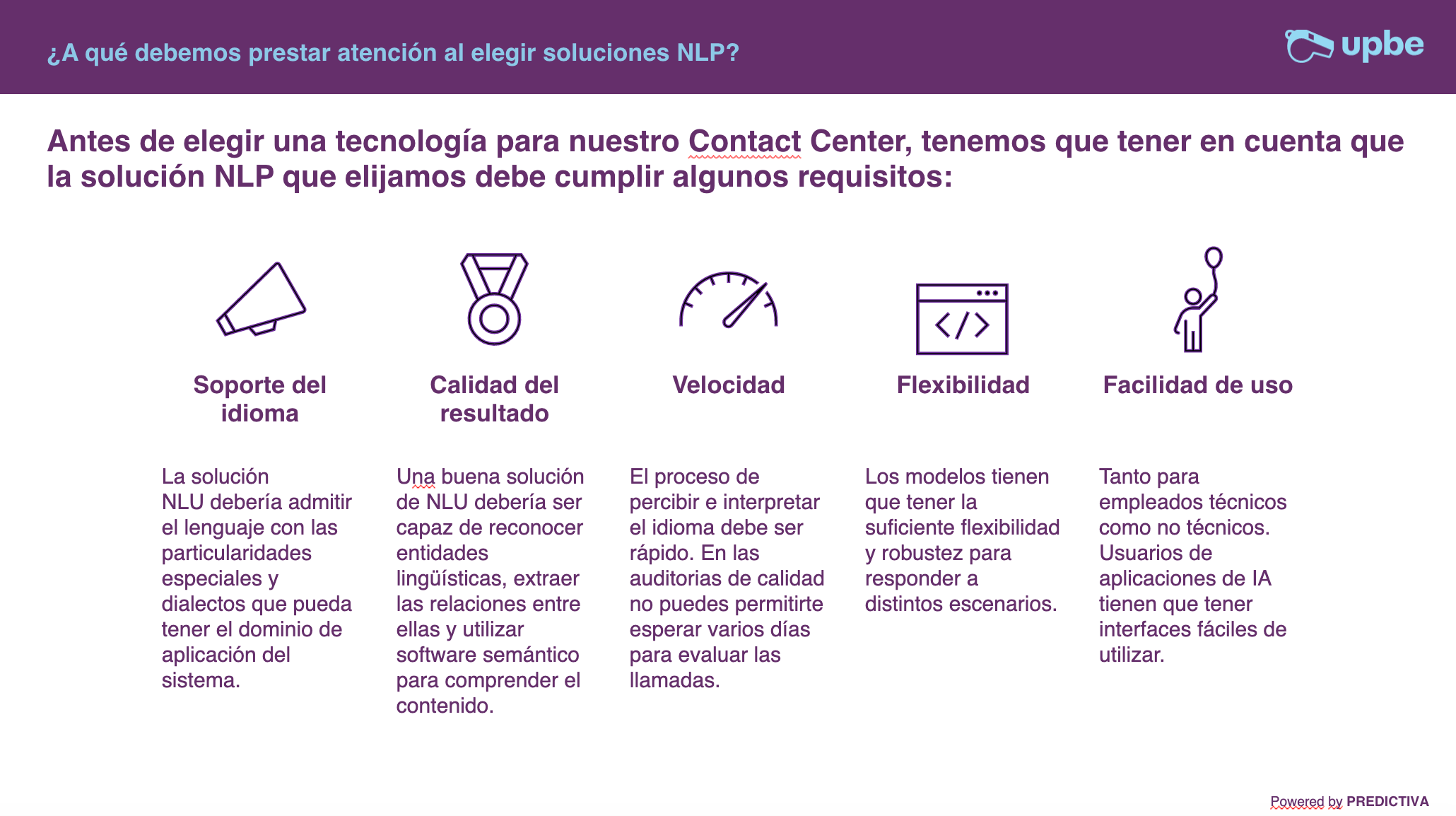
El Machine Learning o Aprendizaje Automático es una rama de la IA que conlleva un método de análisis de datos. Estos métodos están basados en la idea de que los sistemas pueden aprender a partir de esos datos, identificar patrones y tomar decisiones sin la ayuda de un ser humano. ¿En dónde se aplica hoy por hoy el ML y cómo facilita nuestras tareas diarias?
Aplicación de Machine Learning sobre reconocimiento de imágenes
Seguramente os será familiar el reconocimiento de las imágenes. Un smartphone es capaz de hacer este reconocimiento mediante un software que utiliza un modelo de ML entrenado para identificar imágenes.
El modelo de ML que utiliza el software ha sido entrenado con imágenes etiquetadas que definen lo que representa cada imagen. Supongamos que en un número significativo de imágenes se etiquetan a las personas, las farolas o las estatuas. Una vez que este modelo es entrenado adecuadamente, tiene la capacidad de identificar en nuevas imágenes, que no se han utilizado en el entrenamiento, a personas, farolas o coches.

El software identifica características en cada imagen y utiliza las similitudes para asignarle una tipología. Para ello analiza cada pixel o grupos de píxeles. Cuando una máquina procesa una imagen interpreta y analiza los pixeles que son la menor unidad homogénea en una imagen.

Por ejemplo, en el caso de una persona, podría identificar características comunes como la estructura del cuerpo, las piernas, los brazos o la cabeza. La máquina no conoce realmente el significado de un brazo o una pierna, pero sí observa que son elementos comunes en las fotografías etiquetadas como personas.
Entonces aprende que en el futuro tendrá que identificar estos elementos para poder reconocer a personas en otras fotografías. Lo que conseguimos a través de un algoritmo es a enseñar a un software a reconocer tipos de elementos y cómo asociarlos.
Técnicas para implementar Machine Learning
Estas técnicas están en constante evolución, cada día disponemos de ordenadores más complejos que pueden almacenar y procesar más información. Pero vamos a resumir los diferentes tipos de aprendizaje de Machine Learning:
Aprendizaje Supervisado (Supervised Learning)
El ejemplo que acabamos de ver sobre el reconocimiento de imágenes sería una muestra de aprendizaje supervisado. Usándola, se entrena al algoritmo otorgándole las preguntas, denominadas características, y las respuestas, denominadas etiquetas. Esto se hace con la finalidad de que el algoritmo las combine y pueda hacer predicciones.
El aprendizaje supervisado se suele usar en:
- Problemas de clasificación (predecir clientes que se darán de baja, diagnóstico de enfermedades o detección de fraude de identidad).
Veamos un ejemplo sencillo con una muestra de diferentes animales.

Resultado después de aplicar un algoritmo de clasificación:
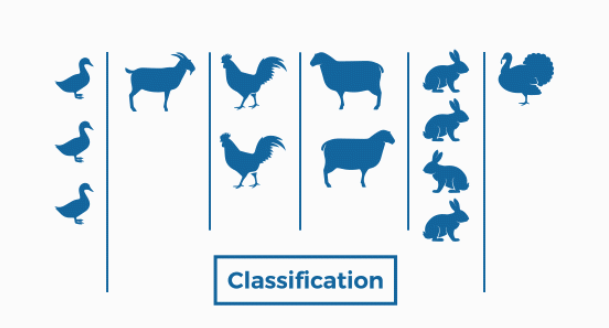
En este caso vemos que la similitud de las imágenes facilita el trabajo de clasificación del algoritmo.
- Problemas de regresión (predicciones meteorológicas, de expectativa de vida, de crecimiento, etc.).
Esta regresión lineal permite predecir de una forma sencilla la relación entre salario y años de experiencia. Los puntos verdes representan a personas y relacionan sus años de experiencia con su salario. La línea de regresión trazada nos permite predecir, para una experiencia determinada, qué salario se esperaría de la misma en base a los casos representados.
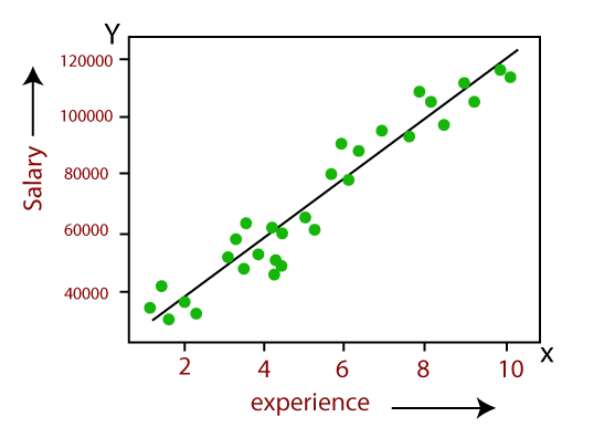
La predicción de estos problemas, que tienen un gran impacto en nuestra vida, se han visto mejoradas drásticamente gracias al Machine Learning. Ningún humano tiene la capacidad de procesar tantos datos y obtener conclusiones con estos niveles de precisión.
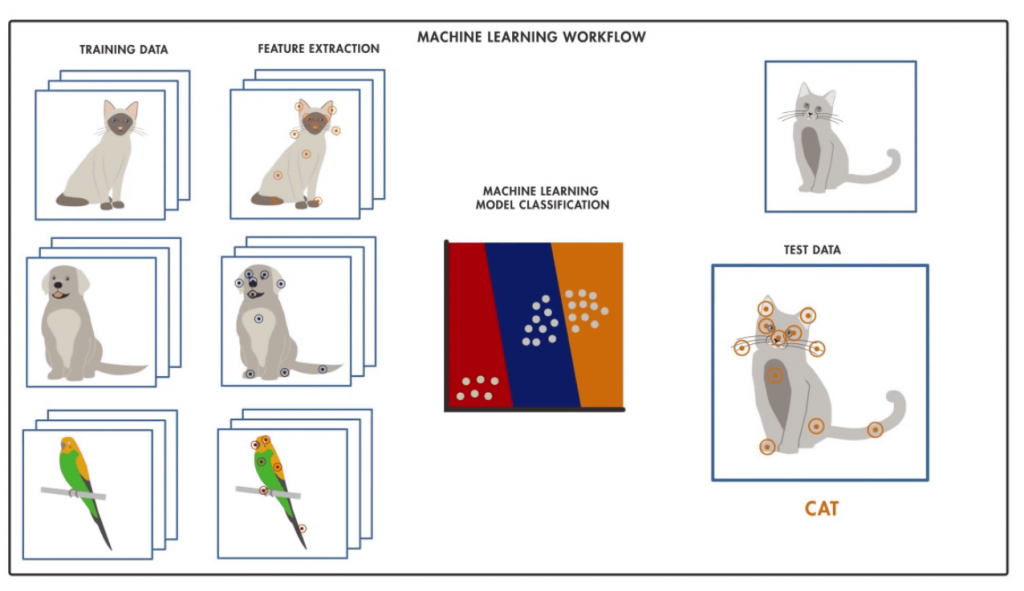
En el siguiente ejemplo vemos básicamente cómo funciona el flujo de trabajo del Machine Learning (aprendizaje automático).
- Se proporcionan imágenes con una etiqueta que representan un animal. Este caso representa imágenes de gatos, perros y también de loros.
- En el proceso de extracción de características se identifican parámetros que son comunes a cada conjunto de animales. Y en el caso de los gatos la forma de las orejas, los bigotes o las patas son algunos ejemplos.
- El algoritmo de clasificación procesa imágenes de animales que no ha observado en el proceso de entrenamiento e identifica características que sugieren la proximidad a un tipo de animal a otro.
- El algoritmo predice mediante una probabilidad qué tipo de animal es el de la foto analizada.
Aprendizaje no Supervisado (Unsupervised Learning)
A diferencia del aprendizaje supervisado, en el no supervisado solo se le otorgan las características, sin proporcionarle al algoritmo ninguna etiqueta. Su función es la agrupación, por lo que el algoritmo debería catalogar por similitud y poder crear grupos, sin tener la capacidad de definir la individualidad de cada uno de los integrantes del grupo. Veámoslo a continuación con ejemplos.
Diferencia práctica entre Aprendizaje Supervisado y No Supervisado
En el aprendizaje supervisado el modelo es entrenado con fotos que han sido identificadas como patos o conejos como mostrábamos anteriormente. El algoritmo utiliza estas etiquetas para encontrar patrones comunes. Por ejemplo, la silueta, las patas o el plumaje.
En aprendizaje no supervisado, un conjunto de fotografías sin identificar son procesadas por el algoritmo. El resultado de este algoritmo es la clasificación de estas fotografías en grupos con características comunes.
No identifica si son patos o conejos porque no le hemos proporcionado esta información como en el caso del aprendizaje supervisado. Sin embargo, sí es capaz de detectar que ciertas fotografías tienen características comunes y las asocia en base a estas características.
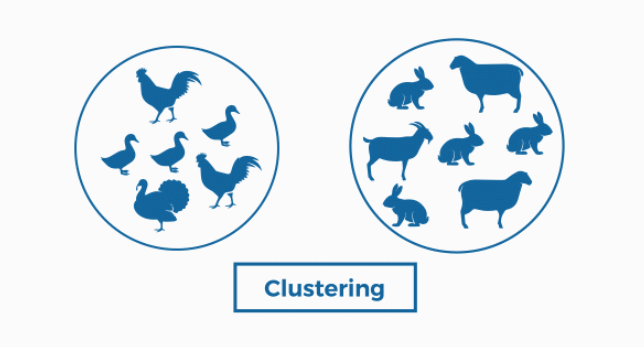
Ejemplo: Volvemos a proporcionar una muestra de animales sin ninguna etiqueta (sin especificar qué tipo de animal es cada imagen) y utilizamos un algoritmo de clustering que básicamente supone agrupar las imágenes en base a características similares.

Para resolver este problema, el algoritmo de clustering no sabe que es un conejo o un pato. Sin embargo, la agrupación que acaba realizando, diferencia a las aves de los mamíferos. ¿Cómo ocurre esto, si no conoce el significado de pato o conejo y menos de lo que es un mamífero?
La respuesta es que, como veíamos antes, identifica características similares entre las aves, dos patas, una morfología parecida, un pico, plumaje. En el caso de los mamíferos, identifica una morfología distinta, tienen cuatro patas, orejas o cuernos, etc.
También existe la posibilidad de combinar ambas técnicas mediante lo que se denomina aprendizaje Semi Supervisado (Semi Supervised Learning). En este caso la entrada de datos que recibe el algoritmo sería una mezcla entre datos etiquetados y datos que no lo están.
Siguiendo el ejemplo anterior, fotos de gatos y perros etiquetadas como tal y otras fotos sin etiqueta (tal y como recibe el modelo no supervisado). Como resultado, el algoritmo trataría de predecir para nuevas fotografías si estas fueran de perros o gatos.
Mejora del modelo: aprendizaje con refuerzo (Reinforcement Learning)
A diferencia de las técnicas anteriores, el Reinforcement Learning intentará hacer aprender a la máquina basándose en un esquema de “premios y castigos”. Esto se hará en un entorno en el que hay que tomar acciones y que está afectado por múltiples variables que cambian con el tiempo.
Una analogía de esta técnica sería el adiestramiento tradicional de un perro al que damos un premio cada vez que cumple la acción que pretendemos. El perro va a identificar esa acción con la recepción de un premio y será mucho más propenso a cumplir esa acción cuando se lo pidamos. En el caso de las máquinas el premio se traduce en un sistema de reconocimiento en el que se premia la acción deseada.
Curso de IA aplicada a negocio
Este texto es parte de nuestro curso de Inteligencia Artificial aplicada a negocio. Son 9 entregas que recibirás en tu correo y que te ayudarán a entender mejor la IA y cómo se aplica en los negocios. Es un curso de iniciación, hecho por personas de negocio para personas de negocio. Aquí tienes toda la información.




8 Comments
Comments are closed.